(2) Weibo-archiver 存档你的微博 | 开发记录
Warning本文发布于 2024/02/07,内容可能已过时。
项目地址:Chilfish/Weibo-archiver,前一集
最认真的一集
在忙完烦人的期末作业后,总算是想着拾起这个项目了 😅 随着用的人多了起来,以及竞品 (雾) speechless 大重构了,还用 Electron 发了桌面版,就想着应该也动手了起来
一个有趣的现象是,脚本已经有好几百的下载量了,但 preview.zip 却没什么人下载,虽然已经在文档说得较为清楚了 hhh。于是加了个导出时顺带自动下载它
最受宠若惊的是,想着试着把赞赏码放上去时,第二天就收到 ¥50 的打赏了……连忙把赞赏列表给刻在网站上了 sponsors
再见了,饿了么
一开始图方便,就用了饿了么的组件库。但到后面,有时候太多的 hack 方法,和实在是看着不是很顺眼,于是就迁移到了 naive-ui
但没想到的是,麻烦事又多了起来 hhh 还是因为油猴的部分,在打包到外部引用时,一开始我用的是 auto-import 来自动导入组件,但最终打包的时候它总会打进很多没用上的组件和函数。最终的解决方式还是在 monkey 的 monorepo 中手动全局注册用到的组件
但它用起来实在是舒服太多了,虽然还是有一些要手动修复的 hack bug
噢我的路由参数们
很多 bug 还是我自己平时要用的时候才发现的,开发时就没想到……
在加功能的时候,想着将分页的状态 (pageSize、page) 添加到 url 中,这样不论是刷新还是什么都能保持了。组合式的 composable 函数是真的舒服,虽然不知道这么写 Pinia 对不对
const route = useRoute()const router = useRouter()
const curPage = computed({ get: () => Number(route.query.page) || 1, set: (val: number) => router.push({ query: { ...route.query, page: val, }, }),})
const pageSize = computed({ get: () => Number(route.query.pageSize) || 10, set: (val: number) => router.push({ query: { ...route.query, pageSize: val, }, }),})更现代的 monorepo
因为要开桌面版,于是先搜了一堆 electron 相关的最佳实践,发现它们的目录结构都是 /packages 放共用、核心的部分,在 /apps 则是最终的应用,如官网、web 版、桌面版等等
于是我也学着重构了一番:[pull:refactor:monorepo directory structure #8],换了些更有意义的文件夹命名
麻烦的图片
才发现图片懒加载一直都没凑效过,于是还是手动用经典的 IntersectionObserver 来为所有的图片懒加载了:lazyLoadImages。默认的 src 是一张占位图,滑动到它时再动态更换到 data-src 里的链接
再就是 Gallery 的宫格图片了,样式是真的难调…… CSS 好难 hhh
规划项目
写了好几个小东西过后,逐渐意识到尽早规划的重要性 😅 边写边改、后续回过头来再改实在是太痛苦了,以及为了提醒自己、告知用户 (画饼),完善了 README 的说明、加了一个项目规划,并用 todoist 来写好代办
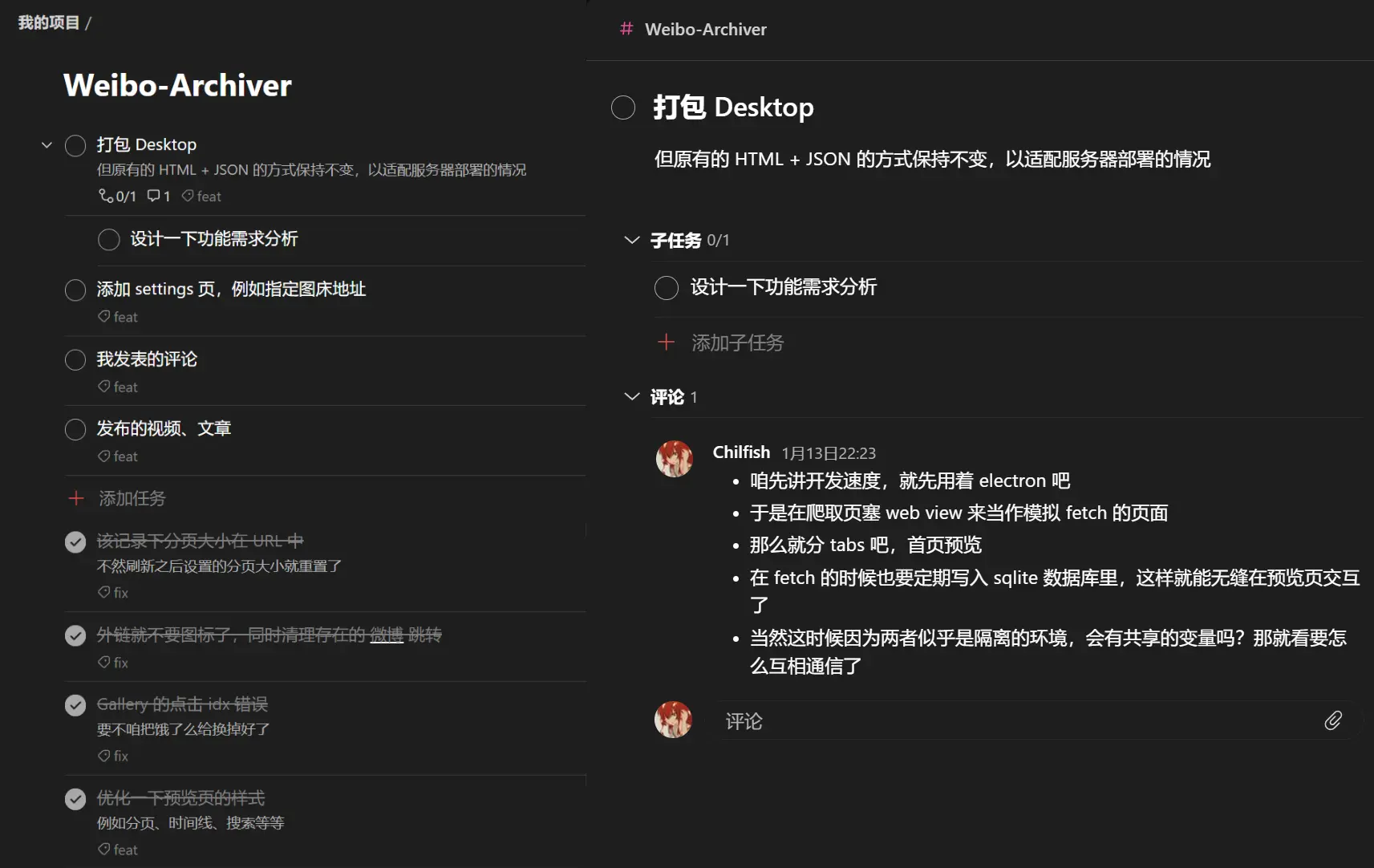
同时,在每次完成之后的划掉它的感觉是真的舒服 🥳 成就感超大,超可视化。接下来就是先试手 Electron 开发,之后再迁移过去了
最注重用户体验的改动
后知后觉地意识到现在地操作实在是有些复杂,下载完图片之后,把数据文件 data.mjs 复制到 web 页面打包的 assets 文件夹里,然后启动 vite 服务器 😅
改为在线服务平台的形式
突然地想到了 https://chatkit.app,它也是一个基本没后端数据库 (抛开接口代理和在线分享来说),所有的交互、数据都存在用户浏览器本地中。或许我也可以改成这样的形式?详见讨论 #26
我将 web 页面部署到了 vercel 上,用户只要将脚本页导出的数据 weibo-data.json 导入 weibo.chilfish.top 就能够在线查看了。然后我找了个解析微博图片的 ipfs 图床,这样图片也不必一定要下载了 🥳
这简直就是天才想法 hhh 而且这么做最大的一个好处就是,我经常改 web 的一些 ui 和逻辑,要发布的时候就不会像以前一样都要开 release (用户迁移的时候也很麻烦,要复制替换原先的数据文件),而是直接 push 给 vercel 自动部署,只要刷新一下缓存就能体验到改动
而分享给其他人的时候,只需要将数据文件一同发送过去、导入就行了 😎 (感觉可以选择范围到导出数据)
数据都存在 indexedDB 里
相对地,数据使用 indexedDB 存在浏览器里,它是 NoSQL 的一种,能实现很多像是建立索引、游标分页等操作,这比以前全加载到内存里操作 json 好多了。记在了 [pr:indexedDB #23]
使用的是 jakearchibald/idb 强大的 indexedDB 库,对原生操作基本都完整封装拓展了。只不过在全文搜索时,还是没想好怎么做比较好,毕竟 indexedDB 还是 key-val 式的数据库,一开始还想着先中文分词然后建索引,但最终还是用经典的 fusejs 来实现了
代码在 [core:storage.ts]。越看越觉得写得太厉害了 😎
设置页
想着,既然都能够切换图床 (用 cdn 或是本地图片),那就顺便把设置页面也做了,毕竟 header 没地方放了 hhh
还得是 chatkit.app,抄了它的夜间模式切换的组件 ui、弹窗式的 settings、tab 来切换 setting 和 about 这些类别
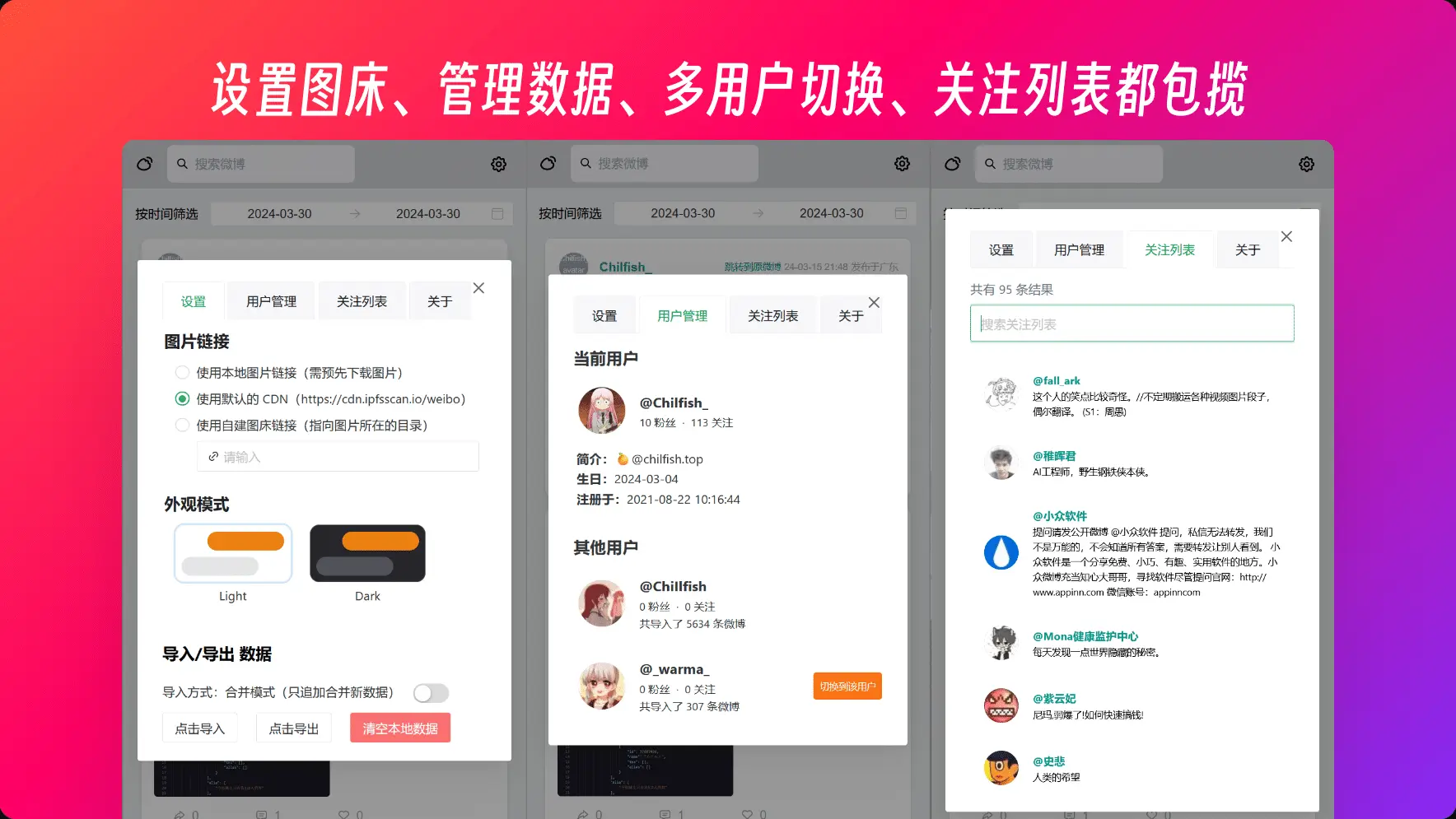
多用户支持
难免会有要备份多个用户的需求,以前都是每个用户都要复制 web 的 dist,再 cd 到对应的目录来启动 vite。但现在既然都存到浏览器里了,那就应该利用上 indexedDB 多表 (类似) 的功能。详见 [pr:multi user #36]
一些元数据都存在 localStorage 里,监听 curUid 的变化,然后改变对应的表名 (每个用户就是一张数据表),同时页面上的微博数据也跟着改变。一切都是响应变化的,速度也超级快
按时间范围筛选
一开始觉得这个不是很必要就没想起要做,但在最近要写总结报告翻微博看看发生了什么时,才意识到漏了什么 (然后总结报告又拖了几天……)
首先我对微博的创建时间建立了索引,这样插入、查询的时候就能按时间来排序了,然后配合上分页的的游标查询、持久化在 url 中,也不难实现。只是处理边界条件的时候有些棘手了 (鉴定为没有熟练掌握 vue 导致的)
例如范围 a 里有 300 条微博,用户切换到了第 25 页,这是他想切到只有 10 条微博的时间范围 b 时,这时候还是第 25 页,就导致游标越界了。所以应该改为只要切换时间范围,就把页码设为 1 就好了 😅
CI/CD 与自动部署
因为这是一个 monorepo,而我仅需要部署里面的 apps/web 部分,同时也只应该下载与它有关的依赖 (总不能让它连 electron 都下了吧)
部署到 vercel 时首先遇到的是找不到输出了,尽管已经指定了输出目录,但却不能识别框架类别,上线全 404……然后才发现要把 project root directory 设为 apps/web,这样就能一键识别了
同时要改一下构建的条件,现在每次推送都会触发构建,有时改的就没涉及到 web 的部分,但好在可以设置 vercel ignored build step
const { VERCEL_GIT_COMMIT_REF, VERCEL_GIT_COMMIT_MESSAGE,} = process.env
// 在 main 分支,commit message 包含 web,或是 release、update deps// 在包含 web 的任何分支// 若不在 main 或 web 分支,则只要 commit message 包含 webconst messages = [ 'release', 'update deps', 'web',]const shouldProceed = messages.some(message => VERCEL_GIT_COMMIT_MESSAGE.includes(message))const isMainBranch = VERCEL_GIT_COMMIT_REF === 'main'const isWebBranch = VERCEL_GIT_COMMIT_REF.includes('web')
if ( (isMainBranch && shouldProceed) || isWebBranch || shouldProceed) { console.log('✅ - Build can proceed') process.exit(1)}else { console.log('🛑 - Build cancelled') process.exit(0)}而我还希望能够每次 push 都构建一份 beta 版本,于是学了一下 GitHub Actions,将构建的产物上传到 artifact 工件里
name: beta Build
on: workflow_dispatch: push: branches-ignore: - monkey paths-ignore: - '**.md' - '.github/**' - '!.github/workflows/**' - 'apps/desktop/**' - packages/database
jobs: install-and-build: runs-on: ubuntu-latest
steps: - name: Checkout uses: actions/checkout@v4
- name: Install Node.js uses: actions/setup-node@v4 with: node-version: 20
- uses: pnpm/action-setup@v3 name: Install pnpm with: version: 8 run_install: false
- name: Get pnpm store directory shell: bash run: | echo "STORE_PATH=$(pnpm store path --silent)" >> $GITHUB_ENV
- uses: actions/cache@v4 name: Setup pnpm cache with: path: ${{ env.STORE_PATH }} key: ${{ runner.os }}-pnpm-store-${{ hashFiles('**/pnpm-lock.yaml') }} restore-keys: | ${{ runner.os }}-pnpm-store-
- name: Install monkey run: pnpm install:monkey
- name: Install Web run: pnpm install:web
- name: build and zip run: pnpm release
- name: upload monkey uses: actions/upload-artifact@v4 with: name: weibo-archiver.user.js path: dist/weibo-archiver.user.js
- name: upload web uses: actions/upload-artifact@v4 with: name: weibo-archiver-webapp path: dist/weibo-archiver-webapp.zip
- name: upload scripts uses: actions/upload-artifact@v4 with: name: weibo-archiver-scripts path: dist/weibo-archiver-scripts.zipCLI 版本
收到了个 CLI 版本的功能请求,要可以在命令行里调用,就能够实现定时运行了。正好也一直很想做一份 CLI,之前重构 core 就是为了能够以库的形式单独运行爬虫,或是在 electron 的 Node 进程里调用
用的是 unjs/citty 库来构建,unjs/unbuild 来打包,又一次地和 rollup 打包器斗智斗勇了好一会 😹
发现为了引用并打包 monorepo 下的其他 package,应该将它放在 devDependencies 下,并将它的依赖放在 peerDependencies 中,这样打包时就能够 tree-shake 地将它们打包在一起了